A Multilayer Network Approach for Guiding Drug Repositioning in Neglected Diseases
Abstract
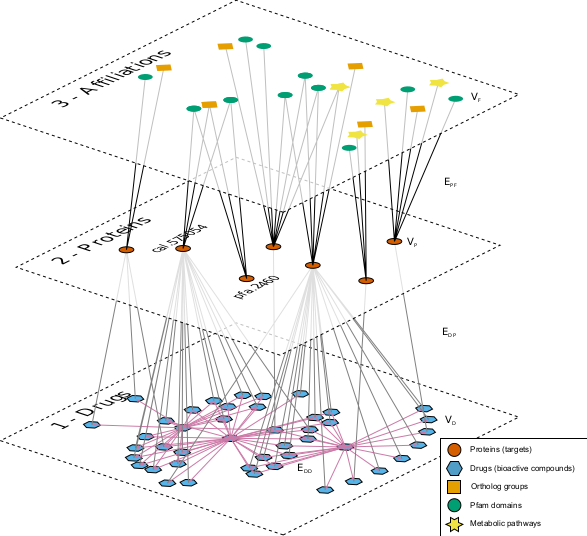
Neglected tropical diseases are human infectious diseases that are often associated with poverty. Historically, lack of interest from the pharmaceutical industry resulted in the lack of good drugs to combat the majority of the pathogens that cause these diseases. Recently, the availability of open chemical information has increased with the advent of public domain chemical resources and the release of data from high throughput screening assays. Our aim in this work was to make use of data from extensively studied organisms like human, mouse, E. coli and yeast, among others, to prioritize and identify candidate drug targets in neglected pathogen proteomes, and drug-like bioactive molecules to foster drug development against neglected diseases. Our approach to the problem relied on applying bioinformatics and computational biology strategies to model large datasets spanning complete proteomes and extensive chemical information from publicly available sources. As a result, we were able to prioritize drug targets and identify potential targets for orphan bioactive drugs.
Fernán Agüero
Principal Investigator, Assistant Professor
Using and generating data to guide discovery of new drugs and diagnostics.