tdrtargets
 TDR Targets Logo, by @leitouran
TDR Targets Logo, by @leitouran
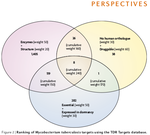
The volume of biological, chemical and functional data deposited in the public domain is growing rapidly, thanks to next generation sequencing, and highly-automated screening technologies. However, there is still a large data imbalance between model, well-funded organisms and pathogens causing neglected diseases (NDs). We developed a chemogenomics resource, (TDR Targets, https://tdrtargets.org), that aims to organize and integrate heterogeneous large datasets with a focus on drug discovery for human pathogens. The database also hosts chemical and genomic data from other organisms to leverage data for comparative and inference-based queries. One of the major impacts of TDR Targets is to facilitate target and chemical prioritizations by allowing users to formulate complex queries across diverse query spaces.
Lionel Urán Landaburu
Former Lab Member (2015 – 2023)
PhD Fellow, teacher and science divulgation enthusiast.
Fernán Agüero
Principal Investigator, Assistant Professor
Using and generating data to guide discovery of new drugs and diagnostics.
Publications
TDR Targets 6: Driving drug discovery for human pathogens through intensive chemogenomic data integration
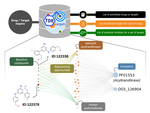
A Multilayer Network Approach for Guiding Drug Repositioning in Neglected Diseases

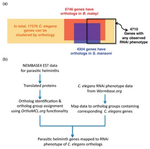
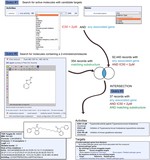
Identification of attractive drug targets in neglected-disease pathogens using an in silico approach